文章目錄
- 什么是Mybatis
- Mybatis的作用是什么
- Mybatis 怎么使用
- 注解的方式
- 注解的多種使用
- @Options注解
- ResultType注解
- XML的方式
- update標簽
- #{} 和 ${}符號的區別
- #{}占位
- ${}占位
- ${}占位的危險性(SQL注入)
- 數據庫連接池
什么是Mybatis
首先什么是Mybatis呢?Mybatis是一個持久層框架也就是用來操作數據庫的一個框架,我們在最原始的時候使用jdbc進行數據庫的操作這使得我們會有大量的重復操作需要進行,那么Mybatis把這些重復的操作進行了集合,使得我們的代碼更見的簡單,并且對于我們jdbc中需要連接數據庫的這個操作也進行了優化,使用配置文件的方式來使得我們的操作變得更加的簡單。
Mybatis的作用是什么
那么看了上面之后我們也就知道了Mybatis框架的作用了也就是簡單易用,代碼簡單提供了很多強大且方便的功能幫助我們可以更好更快更方便的編寫代碼。操縱數據庫。
Mybatis 怎么使用
那么有了上面的概念之后,我們來講述一下Mybatis該怎么使用,首先我們要想使用Mybatis那么我們就要先將Mybatis配置到我們的Spring中也就是說要導入依賴導入什么依賴呢?如下
<dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>3.0.3</version></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter-test</artifactId><version>3.0.3</version><scope>test</scope></dependency>
當然這些還是不夠因為我們只是把Mybatis引入了進來但是我們還是不能使用,我們可以想一下我們在使用jdbc的時候除了把jar包引入進來之后我們還做了什么工作嗎?我們還有的工作就是使用jdbc給我們提供的接口來與我們的目標數據庫建立了連接,那么我們這里也是需要建立連接的,那么連接如何建立呢?
spring:application:name: Spring_Mybaitsdatasource:url: jdbc:mysql://127.0.0.1:3308/mybatis_test?characterEncoding=utf8&useSSL=falseusername: rootpassword: ”寫上自己的密碼“driver-class-name: com.mysql.cj.jdbc.Driver
mybatis:# 配置 mybatis xml 的文件路徑,在 resources/mapper 創建所有表的 xml 文件mapper-locations: classpath:mybatis/**Mapper.xmlconfiguration: # 配置打印 MyBatis日志log-impl: org.apache.ibatis.logging.stdout.StdOutImplmap-underscore-to-camel-case: true #配置駝峰自動轉換
這就是我們配置文件的書寫格式我們發現我們的配置文件內定義了我們mybatis的日志信息并且害配置了mybatis如果進行了xml中寫的話那么我們也配置了該xml文件的路徑信息。那么配置好后我們來看看如何來寫代碼吧
注解的方式
首先是注解的方式我們的Mybatis寫sql代碼實在接口類中寫的因此我們要先定義一個接口代碼并且這個接口代碼我們需要使用@Mapper注解來修飾代碼如下
package com.example.spring_mybaits.mapper;import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Options;
import org.apache.ibatis.annotations.Update;
import java.util.List;
@Mapper
public interface UserInfoMapper {
}
這里我們定義了一個接口并且使用了Mapper注解進行了修飾那么接下來我們要來寫代碼了,那么代碼該怎么去寫呢?那么代碼的書寫我們先從最簡單的查詢所有數據開始吧,如何查詢所有的數據呢?我們來寫一下代碼首先,先在接口中寫一個select方法的聲明
package com.example.spring_mybaits.mapper;import org.apache.ibatis.annotations.*;import java.util.List;@Mapper
public interface UserInfoMapper {List<UserInfo> selectAllUser();
}
第二步實現
package com.example.spring_mybaits.mapper;import org.apache.ibatis.annotations.*;import java.util.List;@Mapper
public interface UserInfoMapper {@Select(" select * from userinfo")List<UserInfo> selectAllUser();
}
第三步進行測驗
我們需要進行實現test方法那么如何快速的實現test方法呢?我們要進行
首先點擊Generate 彈出下面的這個頁面
然后點擊Test
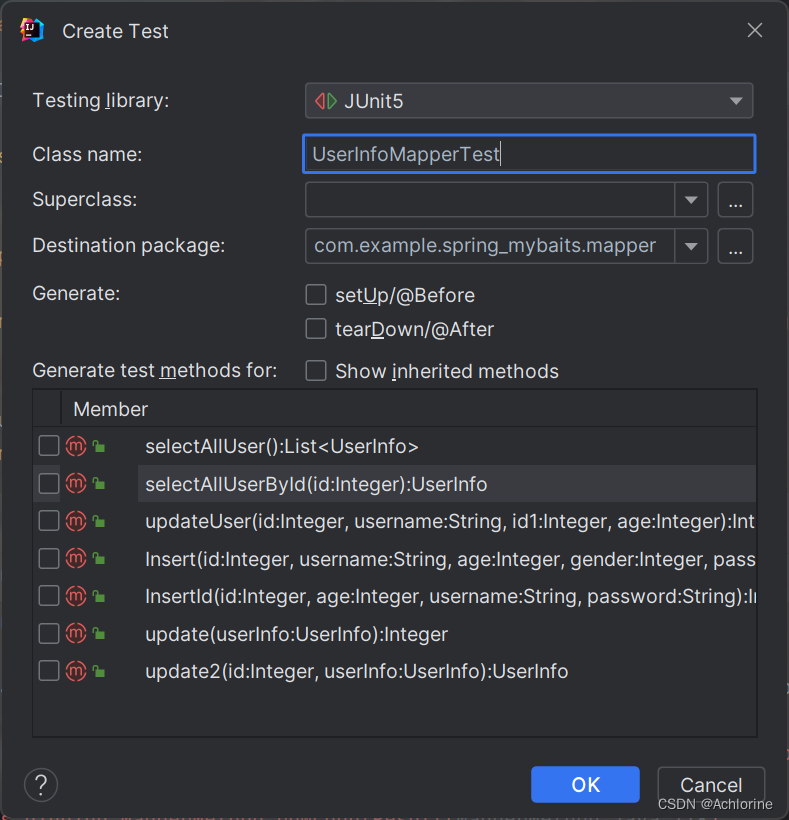
然后在下面選擇你要進行測驗的方法,然后光有這些也不夠我們的測試代碼也是需要進行進一步的書寫的。
package com.example.spring_mybaits.mapper;import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.util.List;import static org.junit.jupiter.api.Assertions.*;
@SpringBootTest
class UserInfoMapperTest {@AutowiredUserInfoMapper userInfoMapper;@Testvoid selectAllUser() {List<UserInfo>list=userInfoMapper.selectAllUser();for (UserInfo u:list) {System.out.println(u);}}
}
我們通過查看上面的測試代碼我們不難發現,我們實現的接口在這里使用了@Autowired注解進行了修飾,那么這個注解我們之前講過這相當于是把spring容器中存儲的Bean給注入了進去,那么既然如此我們就可以調用這個接口中的方法了。
注解的多種使用
@Options注解
這個注解可以幫助我們獲取到查詢到的目標主鍵,比如說我們使用insert插入了一行,然后我們想知道插入的這一行,所被分配到的自動遞增的Id是多少,我們可以通過@Options注解進行實現。這個注解的使用方式如下首先這個注解我們需要傳遞進去兩個參數代碼如下我們來分別說一下他們的作用
@Options(useGeneratedKeys = true,keyProperty = "id")Integer InsertId(Integer id,Integer age,String username,String password);
useGeneratedKeys :它可以是的Mybatis使用JDBC的getGeneratedKeys方法取出由數據庫內部生成的主鍵
keyProperty :指定能夠唯一識別的對象屬性,MyBatis 會使? getGeneratedKeys 的返回值或insert 語句的 selectKey ?元素設置它的值,默認值:未設置(unset)
注意!注意! 設置 useGeneratedKeys=true 之后, ?法返回值依然是受影響的?數, ?增id 會設置在上
述 keyProperty 指定的屬性中
ResultType注解
在我們注解方式去實現的時候我們需要注意到一些特殊的情況比如說我們想要設置其返回的形式,通常適用于我們在寫查詢語句的時候進行的我們來看一下示例代碼
import org.apache.ibatis.annotations.Select;
import org.apache.ibatis.annotations.ResultType;public interface UserMapper {@Select("SELECT * FROM users")@ResultType(User.class)List<User> getAllUsers();
}
那么這里的映射其實就是將結果進行映射,那么這時候會有疑問假如說我們要進行復雜查詢的話我們要對多個結果進行映射的話該怎么做呢?那么這時候需要用到新的注解叫做@Results,那么我們來舉個例子
@Results({@Result(property = "id", column = "id"),@Result(property = "name", column = "name"),@Result(property = "email", column = "email")})
它的名字和它的用法很像,指的就是多個result的集合。那么它的一個樣例代碼如下
import org.apache.ibatis.annotations.Select;
import org.apache.ibatis.annotations.Results;
import org.apache.ibatis.annotations.Result;public interface UserMapper {@Select("SELECT id, name, email FROM users")@Results({@Result(property = "id", column = "id"),@Result(property = "name", column = "name"),@Result(property = "email", column = "email")})List<User> getAllUsers();
}
XML的方式
除了使用上述注解的方式之外我們還可以使用XML的方式,那么XML的方式該怎么實現呢?我們首先要先對前面的一個知識點做一個說明那就是我們在配置文件中的下面的這個屬性我們可以根據意思去揣測出來這個意思是指路徑
mapper-locations: classpath:mybatis/**Mapper.xml
那么這個路徑其實就是我們的xml文件所配置的路徑,那么接下來我們來寫一下xml中的格式。首先是XML中的一些配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.spring_mybaits.mapper.UserInfoMapper">
</mapper>
那么我們來講解一下這個配置首先第一個mapper,他是一個標簽,我們接下來寫的所有標簽都是在這個標簽內部進行寫的,其次就是namespace這個英文的直譯就是命名空間,也就是我們這個xml文件是對那一個java文件所進行的連接,那么接下里我們來用幾個例子來寫一下吧
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.spring_mybaits.mapper.UserInfoMapper"> <update id="updateUser">UPDATE userinfo set username=#{username},id=#{id1},age=#{age} WHERE id=#{id};</update>
</mapper>
Integer updateUser(Integer id,String username,Integer id1,Integer age);
然后我們用上面寫的知識首先在方法的聲明這里鼠標右鍵點擊一下
在彈出的頁面中選擇Generate
然后選擇test
然后在生成的test方法中實現我們的測試方法。
@Testvoid updateUser() {UserInfo userInfo=new UserInfo();userInfo.id=11;userInfo.age=21;userInfo.phone="520134";userInfo.username="zyficl";int d= userInfoMapper.updateUser(2, userInfo.username,userInfo.id, userInfo.age );System.out.println(d);}
通過上面我們來回答一下上面代碼中可能出現的部分疑問
update標簽
首先就是update標簽,通過這標簽的內容我們可以指導這個標簽中需要有一個參數那就是id這個id的值就是我們具體要實現的一個方法的名稱,然后我們以此作為類推我們可以知道,其實我們的select標簽也是同樣的用法。
那么我們有了上面的了解后相信就可以寫出比較簡單的一些數據庫sql語言的操作了,那么這些操作包括但不限于增刪查改,但是接下來還有一些比較復雜的操作也是需要我們學習的比如說復雜查詢,排序,等,包括一些動態的添加,動態的查找等,那么我們來一起學習一下這些該怎么進行那么接下來我們來講一下本節重點知識那就是#和$符號的區別。
#{} 和 ${}符號的區別
那么在討論區別之前我們需要先討論一下他們的作用,那么他們的作用是什么呢?他們的作用其實都是對sql語句加上參數也就是一個占位符,但是他們在實現上又有區別,我們下面可以來看一下分別使用這兩個符號的話會有什么不同
#{}占位
這是一個安全的占位當我們使用這個占位的時候我們發現我們打印出的日志中對于占位的內容并沒有補充,也就是說此時的占位并不是直接補充的。我們輸?的參數并沒有在后?拼接,id的值是使? ? 進?占位. 這種SQL 我們稱之為預編譯SQL

${}占位
當我們把占位符更改一下更改為${}占位后我們再來看一下此時我們的代碼會變成什么樣子的呢?

這時候我們發現我們的代碼變成了占位符的直接拼接,不像上面的那種使用占位符進行拼接那么這種方式我們叫做即時SQL。這也就是這兩個的區別
${}占位的危險性(SQL注入)
$ 占位符用于直接替換字符串,這種方式不進行參數轉義,因此存在SQL注入的風險。它通常用于傳遞表名、列名等SQL片段,但絕不應該用于傳遞用戶輸入的數據。那么什么時sql注入呢?比如說下面的這個語句
SELECT * FROM userinfo where id=?;
這里的問號是我們需要填寫的內容那么既然如此假如說我們使用的時$占位符的話我們是不是也就是可以傳進去這樣一個內容呢?
SELECT * FROM userinfo where id=1;DELETE userinfo;
因為那個?表示并不是一個單一的字符因此我們完全可以將這個內容改成這個樣子也正因此當我們執行的時候我們就會發現完了,sql語句被注入了,因此這樣就會導致我們發生一個難以想象的一個損失。比如說被刪庫等操作。因此我們在實際開發中會盡量避開使用$符號。但是話又說回來了,為什么我們要保留這個符號呢?其實原因也很簡單因為有些地方我們不可避免的要使用這個符號就比如說排序查詢
使用 ${sort} 可以實現排序查詢, ?使? #{sort} 就不能實現排序查詢了
除此之外還有別的嗎?當然還有,也就是我們的模糊查詢(like查詢)
@Select("select id, username, age, gender, phone, delete_flag, create_time,
update_time " +"from userinfo where username like '%#{key}%' ")
List<UserInfo> queryAllUserByLike(String key);
但是這里我們會陷入一個非常糾結的地方那就是如果我們使用$符號會有sql注入的風險可是不適用的話又不能達到我們的需求,那這個該怎么辦呢?我們需要借助一個方法來進行實現這個方法就是concat方法,這個方法的作用是什么呢這個方法的作用是進行字符串的拼接,也就是說我們可以使用字符串拼接的方式來避免這個風險那么樣例如下
@Select("select id, username, age, gender, phone, delete_flag, create_time,
update_time " +"from userinfo where username like concat('%',#{key},'%')")
List<UserInfo> queryAllUserByLike(String key);
數據庫連接池
池化技術相信我們都已經了解過了池化技術相當于一個中間商一樣我們對有無池化技術來用一張圖來說明一下
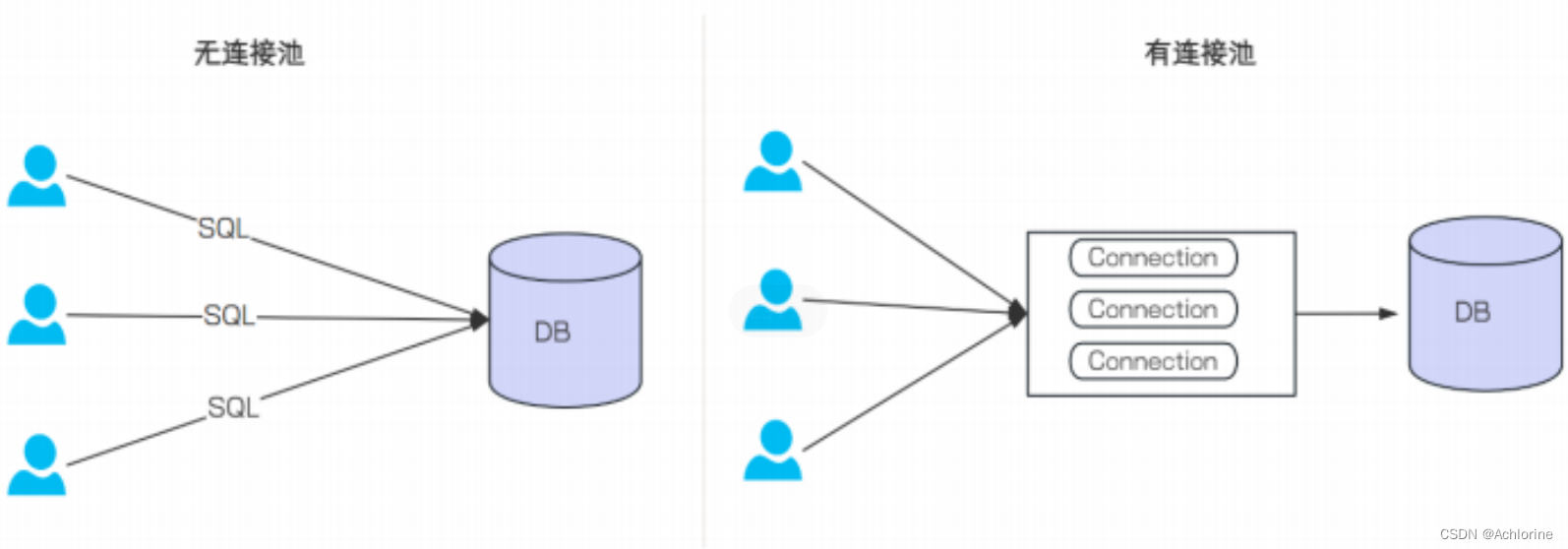
這張圖可以有效的說明有無池化技術的區別。
沒有使?數據庫連接池的情況: 每次執?SQL語句, 要先創建?個新的連接對象, 然后執?SQL語句, SQL
語句執?完, 再關閉連接對象釋放資源. 這種重復的創建連接, 銷毀連接?較消耗資源
使?數據庫連接池的情況: 程序啟動時, 會在數據庫連接池中創建?定數量的Connection對象, 當客?
請求數據庫連接池, 會從數據庫連接池中獲取Connection對象, 然后執?SQL, SQL語句執?完, 再把
Connection歸還給連接池
那么我們的連接池有哪些呢?如下
常?的數據庫連接池:
? C3P0
? DBCP
? Druid
? Hikari
我們來看一下我們的Mybaits的日志信息我們是可以發現的

在這里我們發現我們的Mybaits使用的一個數據庫連接池是一個hikari,那么這其實也是可以更改的。
如果我們想把默認的數據庫連接池切換為Druid數據庫連接池, 只需要引?相關依賴即可






)






:跟著鬼谷子學溝通—“飛箝”之術)





