
文章目錄
- 一,DETR
- 1. 簡介
- 2. 亮點
- 3. 細節
- 4. 總結一下
- 二,GroundingDINO
- Grounding DINO的整體流程
- Grounding DINO的目標函數
一,DETR
之前的目標檢測框架,需要很多的人工干預,很多的先驗知識,而且可能還需要很復雜的普通的庫不支持的一些算子。
DETR 既不需要proposal, 也不需要anchor,用transformer這種能全局建模的能力,從而把目標檢測看成一個集合預測的問題。
因為有了這種全局建模的能力,DETR不會輸出那么多冗余的框,而不需要nms,做后處理,讓訓練和部署都簡單了不少。
1. 簡介
- 把目標檢測 看成 集合預測 的問題。
- 給定一堆圖片,預測這些框的坐標和類別
- 這個框就是一個集合
- 任務就是給定一個圖片,我要去把這個集合預測出來
- 把目標檢測 做成了 端到端 的框架
- 把之前目標檢測特別依賴人的部分 (設定anchor, nms) 去掉了,就沒有那么多的超慘需要去調,整個網絡就變得非常簡單了
2. 亮點
- DETR提出了一個目標函數
- 使用了transformer encoder-decoder架構
- 還有一個learned object queries
-
而且是并行計算的,一起出框,而不是串行的
-
新的模型很簡答,不需要特殊的庫,支持cnn和transformer庫就可以做
-
在coco表現四十多,比當時最多的低了十個點。
-
DETR也可以去做前景分割,效果很好。
-
建議去讀一下代碼
3. 細節
- 之前的目標檢測器都是間接的去解決問題,用了anchor, proposal, 預測中心點,nms等等。
- DETR 采用了端到端的方式,直接解決問題,簡化了目標檢測的流程。
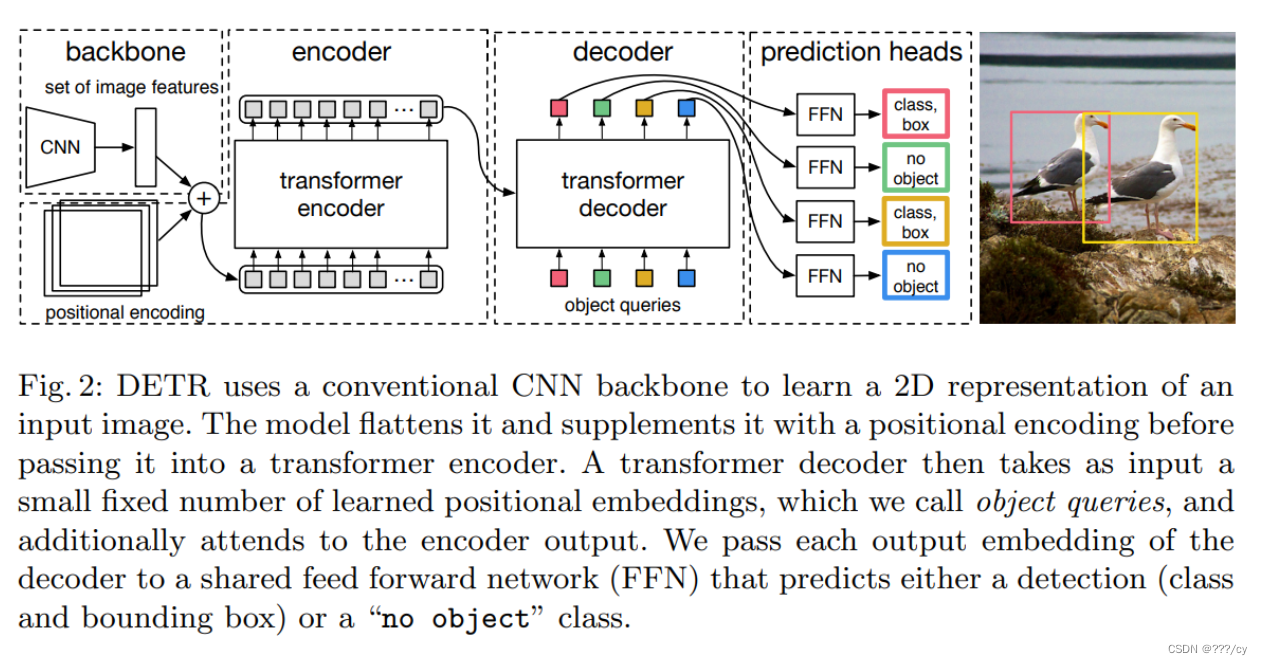
- 用卷積神經網絡抽取一個圖像特征,拉直,送給一個transfomer
- transfomer encoder學習一個全局的信息,為接下來的 decoder(出預測框)來做鋪墊
- 使用transformer encoder, 就意味著每一個特征,都會與全局每一個特征有交互了,這樣她大概就知道哪塊是哪個物體,哪塊又是另外一個物體,對同一個物體來說,只需要出一個框,而不是好多個框。 這種全局的特征,特別有利于去除這種冗余的框。
- 用transfomer decoder 做框的輸出。當有了圖像的特征之后,還有一個object quirer, 它限定了你要出多少個框,通過queire和特征去做交互,在decoder里做自注意力操作,得到了最后輸出的框。
- 作者設定出100個框,100個框如何與ground truth做匹配,計算損失呢?他把這個問題看成一個集合預測的問題,用 二分圖匹配的方法計算這個loss。
- 比如,ground truth有兩個框,通過這輸出的100個框計算與2個框的matching loss,而決定出,在這一百個預測中,哪兩個框是獨一無二的對應到這個紅色和黃色的ground truth框的。一旦匹配好之后,就計算bbox, cls的loss, 對于沒有匹配到的框就會被標記為背景類。
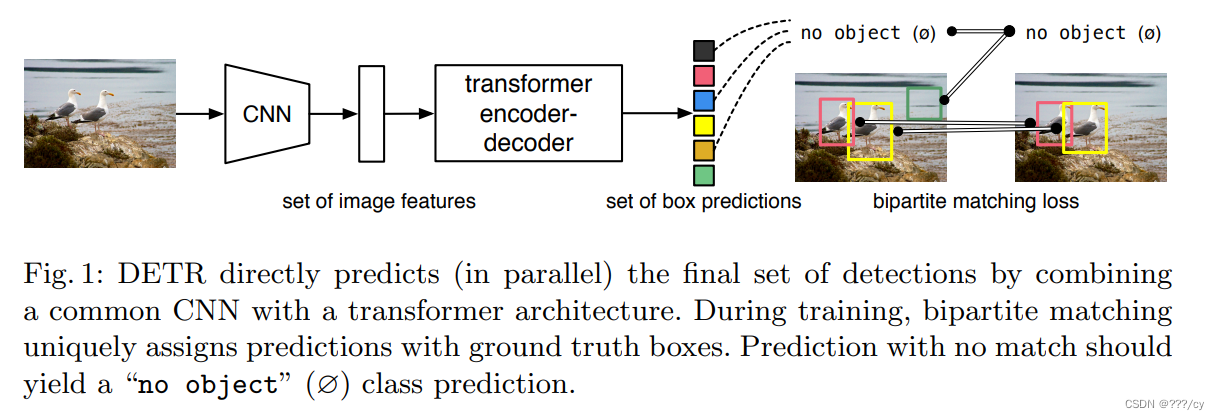
- 比如,ground truth有兩個框,通過這輸出的100個框計算與2個框的matching loss,而決定出,在這一百個預測中,哪兩個框是獨一無二的對應到這個紅色和黃色的ground truth框的。一旦匹配好之后,就計算bbox, cls的loss, 對于沒有匹配到的框就會被標記為背景類。
4. 總結一下
- 四步:
- 用神經網絡抽特征
- 用transformer encoder學全局特征, 幫助后面做檢測
- 用transformer decoder 生成很多的預測框
- 把預測框與ground truth的框做匹配,在匹配上的這些框里面去算目標檢測的損失
-
推理的時候:
前三步都是一致的,直接用閾值,卡一下box preditions的置信度 > 0.7是前景物體, <0.7 就被當作背景物體了。 -
在coco與faster rcnn AP結果差不多,對大物體表現非常好,對小物體小物體效果一般。半年之后有一篇論文解決了這個問題,也解決了DETR訓練太慢的問題。
損失函數:
- 匈牙利損失:基于匈牙利算法進行預測框和真實框之間的匹配,并計算匹配后的分類損失和框回歸損失。
- 分類損失:采用交叉熵損失,用于預測每個框的類別。
- 框回歸損失:采用GIoU損失和L1損失的組合,用于預測框的坐標。GIoU損失是IoU損失的一種改進,考慮了框的大小。
- DICE/F1損失:用于分割分支,用于預測每個框的分割掩碼。
- 輔助解碼損失:在解碼器每層之后添加預測頭,并計算匈牙利損失,有助于模型輸出正確數量的每個類別的對象。
通過匈牙利匹配強制預測唯一對應真實框,同時利用分類、框回歸和分割損失來訓練模型,實現了端到端的檢測和分割。
二,GroundingDINO
GroundingDINO 論文總結
| GroundingDINO 論文的總結,請點擊上方的 跳轉鏈接 |
- 其實和DETR的結構一模一樣,各位reader從以下幾個方面可以自己對比一下。
- encoder-decoder
- object query
- 二分圖匹配
Grounding 與 DETR 的不同:就是引入了文本信息,把文本圖像相互融合了三次。做到文本指導圖片的這么一個能力。

Language-guide Query Selection 給定圖像特征和文本特征,Language-guide Query Selection模塊首先計算兩者的相關性得分,然后根據得分選擇最相關的圖像特征作為queries。這些queries包含了圖像和文本的信息,隨后會被送入解碼器進行進一步處理。
Grounding DINO的整體流程
1. 特征提取: 首先,通過圖像backbone和文本backbone分別提取輸入圖像和文本的特征。
2. 特征增強: 接著,將提取的圖像特征和文本特征輸入特征增強模塊,通過自注意力、圖像到文本的交叉注意力和文本到圖像的交叉注意力實現跨模態特征融合。
3. 查詢選擇: 然后,利用語言指導的查詢選擇模塊,從增強后的圖像特征中選出與輸入文本更相關的特征作為解碼器的查詢。
4. 解碼器: 接著,將選擇的查詢輸入跨模態解碼器,解碼器包含自注意力層、圖像交叉注意力層、文本交叉注意力層和FFN層,用于進一步融合圖像和文本特征,并更新查詢表示。
5. 預測輸出: 最后,利用解碼器最后一層的輸出查詢進行目標框預測和對應短語提取。
6. 損失函數: 在整個流程中,使用對比損失、框回歸損失和GIOU損失進行多任務學習。
總體來說,Grounding DINO通過在特征增強、查詢選擇和解碼器等多個階段進行跨模態特征融合,實現了對任意文本指定的目標檢測。
Grounding DINO的目標函數
- 對比損失(Contrastive Loss):用于預測對象和語言標記之間的分類。使用點積計算每個查詢與文本特征之間的預測logits,然后計算每個logit的Focal loss。
- 框回歸損失(Box L1 Loss):用于預測對象的邊界框坐標。用于計算預測框和真實框坐標之間的絕對誤差。
- GIOU損失(GIOU Loss):用于預測對象邊界框的準確度。用于衡量預測框和真實框的形狀和位置重疊情況,考慮到重疊區域和整體框的面積。
這些損失首先用于進行預測與真值之間的匈牙利匹配,然后計算最終損失。 此外,在模型的每個解碼器層和解碼器輸出之后,還添加了輔助損失。對比損失、框回歸損失和GIOU損失在匹配和最終損失計算中的權重分別為2.0、5.0和2.0。






產品規格說明書)



)



)




