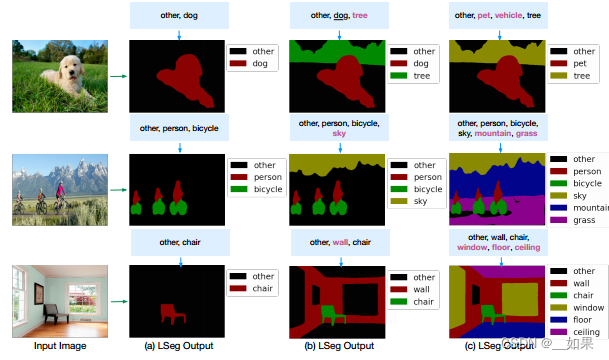
效果很好,文本增加一個詞,就能找到對應的分割地方,給出的無用標簽也不會去錯誤分割,而且能理解文本意思,例如dog和pet都能把狗給分割出來

image encoder使用DPT分割模型,大致架構為ViT+decoder,decoder的作用是把bottleneck feature慢慢upscale上去,得到特征圖
文本和圖片的特征圖的C一般為512或768
將兩個特征矩陣在C維度上相乘,得到HxWxN的矩陣,N是文本標簽個數
將最后的矩陣去和ground truth mask去做交叉熵,而不是像CLIP一樣做對比學習的loss,因此它不是一個無監督學習的工作,是有監督的
創新點在于把文本特征通過矩陣相乘融入圖像特征中
論文中text encoder沿用了凍結的CLIP text encoder,因為分割任務的數據集還是不夠大,fine-tune容易帶偏CLIP預訓練出的參數
spatial regularization block里是conv或者depthwise conv層,目的是為了多理解理解文本和視覺到底應該怎么去交互,2個block效果最好





)

一些常用方法)






)




