本篇文章主要是針對初學者,對正則表達式的理解、作用和應用
正則表達式🌟
- 一、🍉正則表達式的概述
- 二、🍉正則表達式的語法和使用
- 三、 🍉正則表達式的常用操作符
- 四、🍉re庫主要功能函數
一、🍉正則表達式的概述
- 通用的字符串表達框架
- 簡潔表達一組字符串的表達式
- 針對字符串表達“簡潔”和“特征”思想的工具
- 判斷某字符串的特征歸屬
正則表達式在文本處理中十分常用
- 表達式文本類型的特征(病毒、入侵等)
- 同時查找或替換一組字符串
- 匹配字符串的全部或部分
二、🍉正則表達式的語法和使用
-
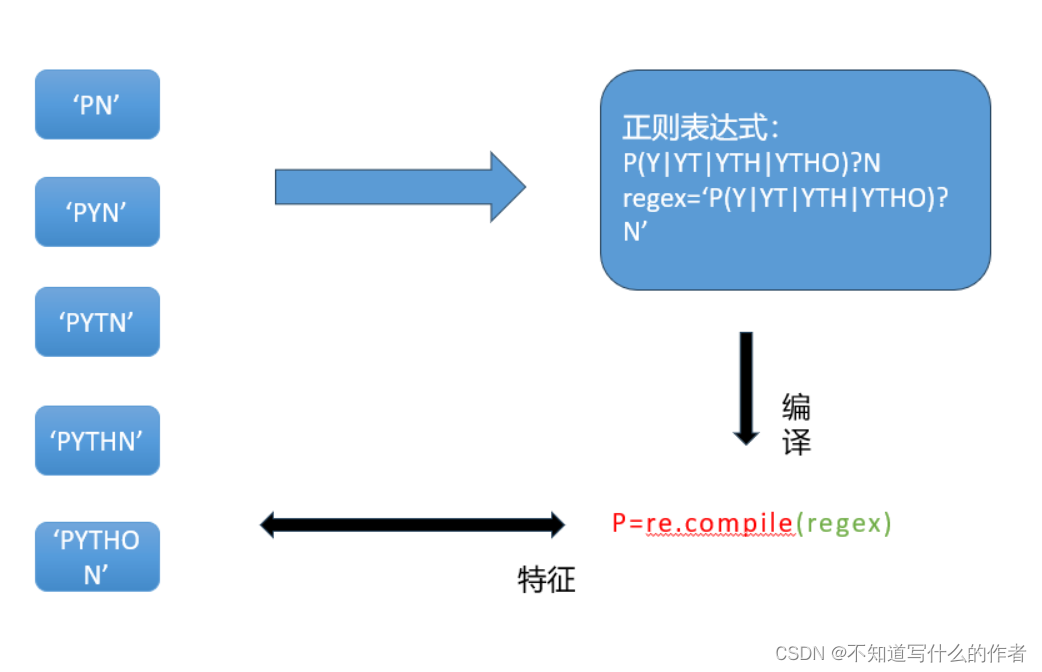
語法:
正則表達式語法由字符和操作符構成
P(Y|YT|YTH|YTHO)?N
-
使用
編譯:將符合正則表達式語法的字符串轉換成正則表達式特征。
三、 🍉正則表達式的常用操作符
| 操作符 | 說明 | 實例 |
|---|---|---|
| . | 表示任何單個字符 | |
| [ ] | 字符集,對單個字符給出取值范圍 | [abc]表示a、b、c,[a-z]表示a到z單個字符 |
| [ ^ ] | 非字符集,對單個字符給出排除范圍 | [^abc]表示非a或b或c的單個字符 |
| * | 前一個字符0次或無限次擴展 | abc*表示ab、abc、abcc、abcc等 |
| + | 前一個字符1次或無限次擴展 | abc+表示abc、abcc、abccc等 |
| ? | 前一個字符0次或1次擴展 | abc?表示av、abc |
| | | 左右表達式任意一個 | abc|def表示abc、def |
| {m} | 擴展前一個字符m次 | ab{2}c表示abbc |
| {m,n} | 擴展前一個字符m至n次(含n) | ab{1,2}c表示abc、abbc |
| ^ | 匹配字符串開頭 | ^abc表示abc且在一個字符串的開頭 |
| $ | 匹配字符串結尾 | abc$表示abc且在一個字符串的結尾 |
| () | 分組標記,內部只能使用|操作符 | (abc)表示abc,(abc|def)表示abc、def |
| \d | 數字,等價于[0-9] | |
| \w | 單詞字符,等價于[A-Za-z0-9] |
四、🍉re庫主要功能函數
| 函數 | 說明 |
|---|---|
| re.search(pattern, string) | 在一個字符串中搜索匹配正則表達式的第一個位置,返回match對象 |
| re.match(pattern, string) | 從一個字符串的開始位置起匹配正則表達式,返回match對象 |
| re.findall(pattern, string) | 搜索字符串,以列表類型返回全部能匹配的子串 |
| re.split(pattern, string) | 將一個字符串按照正則表達式匹配結果進行分割,返回列表類型 |
| re.finditer(pattern, string) | 搜索字符串,返回一個匹配結果的迭代類型,每個迭代元素是match對象 |
| re.sub(pattern, string) | 在一個字符串中替換所有匹配正則表達式的字串,返回替換后的字符串 |
| re.compile(pattern[, flags]) | |
| re.escape(string) |
re模塊中常用函數的簡單介紹:
語法:
re.函數(pattern, string,flags=0)
- pattern:正則表達式的字符串或原生字符串表示
- string:待匹配字符串
- flags:正則表達式使用時的控制標記
-
re.search(pattern, string,flags=0):
在字符串中搜索匹配正則表達式pattern的第一個位置,返回一個匹配對象,如果沒有找到匹配的,則返回None。import re match = re.search(r'\d+', 'hello 123 world') if match:print('找到匹配:', match.group()) else:print('未找到匹配') -
re.match(pattern, string,flags=0):
從字符串的起始位置匹配正則表達式pattern,如果起始位置沒有匹配到,則返回None。注意這與search()不同,search()會掃描整個字符串以查找匹配項。match = re.match(r'\d+', '123 hello world') if match:print('找到匹配:', match.group()) else:print('未找到匹配') -
re.findall(pattern, string):
返回字符串中所有與正則表達式pattern相匹配的所有非重疊匹配項的列表。如果未找到匹配項,則返回空列表。matches = re.findall(r'\b\w+\b', 'Hello World! This is a test.') print(matches) # 輸出:['Hello', 'World', 'This', 'is', 'a', 'test'] -
re.sub(pattern, repl, string, count=0, flags):
將字符串中所有與正則表達式pattern匹配的部分替換為repl,并返回修改后的字符串。count參數可以指定替換的最大次數,默認為0,表示替換所有匹配項。result = re.sub(r'\d+', 'NUMBER', 'hello 123 world 456') print(result) # 輸出:'hello NUMBER world NUMBER' -
re.compile(pattern[, flags]):
編譯正則表達式字符串為一個正則表達式對象,這樣可以提高使用相同模式進行多次匹配的效率。pattern = re.compile(r'\d+') match = pattern.match('123 hello') if match:print('找到匹配:', match.group()) -
re.escape(string):
轉義字符串中的特殊字符,使得它們在正則表達式中作為字面值字符對待。pattern = re.compile(re.escape('[') + r'\d+' + re.escape(']')) match = pattern.search('[123]') if match:print('找到匹配:', match.group()) -
re.split(pattern,string,maxsplit=0,flags=0):
將一個字符串按照正則表達式匹配進行分割返回列表類型
- maxsplit:最大分割數,剩余部分作為最后一個元素輸出
import re result1=re.split(r'[1-9]\d{5}','BIT100081 TSU100084') print(result1) result2=re.split(r'[1-9]\d{5}','BIT100081 TSU100084',maxsplit=1) print(result2) -
re.finditer(pattern, string):
搜索字符串,返回一個匹配結果的迭代類型,每個迭代元素是,match對象
import re for m in re.finditer(r'[1-9]\d{5}','BIT100081 TSU100084'):if m:print(m.group(0))
拓展:
- re庫的另一種等價用法:
# 第一種 函數式用法:一次性操作
rst=re.search(r'[1-9]\d{5}','BIT 100081')
# 第二種 面對對象用法:編譯后的多次操作
pat=ree.compile(r'[1-9]\d{5}')
rst=pat.search('BIT 100081')
-
match對象介紹
Match對象一次匹配的結果,包含匹配的很多信息
import re match=re.search(r'[1-9]\d{5}','BIT 100081') if match:print(match.group(0))print(type(match))match對象的屬性:
屬性 說明 .string 待匹配的文本 .re 匹配時使用的patter對象(正則表達式) .pos 正則表達式搜索文本的開始位置 .endpos 正則表達式搜索文本的結束位置 match對象的方法:
方法 說明 .group(0) 獲得匹配的字符串 .start() 匹配字符串在原始字符串的開始位置 .end() 匹配字符串在原始字符串的結束位置 .span() 返回(.start(),.end()) import re match=re.search(r'[1-9]\d{5}','BIT100081 TSU100084') print(match.string) print(match.re) print(match.pos) print(match.endpos) print(match.group(0)) print(match.start()) print(match.end()) print(match.span()) -
貪婪匹配
Re默認采用貪婪匹配,即輸出匹配最長的字串
import re match=re.search(r'PY.*N','PYANBNCNDN') print(match.group(0))最小匹配:如何輸出最短的子串呢?
import re match=re.search(r'PY.*?N','PYANBNCNDN') print(match.group(0))最小匹配操作符
操作符 說明 *? 前一個字符0次或無限次擴展,最小匹配 +? 前一個字符1次或無限次擴展,最小匹配 ?? 前一個字符0次或1次擴展,最小匹配 {m,n}? 擴展前一個字符m至n次(含n),最小匹配 -
典型例子:
在Python中,可以使用
re模塊(正則表達式模塊)來匹配IP地址。一個基本的IPv4地址由四個0到255之間的數字組成,每部分之間用點(“.”)分隔。下面是一個簡單的例子,展示了如何編寫一個正則表達式來匹配這樣的IP地址:
import redef is_valid_ip(ip):# 定義IP地址的正則表達式ip_pattern = re.compile(r'^((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$')# 使用正則表達式匹配IP地址if ip_pattern.match(ip):return Trueelse:return Falseif __name__ == '__main__':# 測試函數ips = ["192.168.1.1", "255.255.255.255", "123.456.789.0", "1.2.3"]for ip in ips:print(f"{ip}: {is_valid_ip(ip)}")
這段代碼首先導入了re模塊,并定義了一個函數is_valid_ip,該函數使用一個正則表達式來檢查輸入的字符串是否符合IPv4地址的格式。正則表達式的詳細解釋如下:
^:表示字符串的開始。((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}:這部分匹配前三部分的數字,每部分數字范圍是0到255,后面跟著一個點(“.”)。其中,25[0-5]匹配從250到255的數字,2[0-4][0-9]匹配從200到249的數字,[01]?[0-9][0-9]?匹配0到199的數字,包括前導零的情況。\.表示匹配點字符本身(因為點在正則表達式中有特殊含義,所以需要用反斜杠轉義)。
(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$:這部分匹配第四部分的數字,后面跟上字符串的結束標志$。
經典正則表達式實例:
| 表達式 | 解釋 |
|---|---|
| ^ [A - Za-z]+$ | 由26個字母組成的字符串 |
| ^ [A-Za-Z0-9]+$ | 由26個字母和數字組成的字符串 |
| ^- ? \d+$ | 整數形式的字符串 |
| ^ [0-9] * [1-9] [0-9] * $ | 正整數形式的字符串 |
| [1-9] \d{5} | 中國境內郵政編碼,6位 |
| [\u4e00-\u9fa5] | 匹配中文字符 |
| \d{3}-d{8}|\d{4}-\d{7} | 國內電話號碼,010-68913536 |







——IESKF代碼實現)

)










人臉識別系統)